
Introduction
Text annotation is a crucial step in machine learning. It’s the process of labeling text data, providing context and meaning to words.
This process is particularly important in natural language processing, sentiment analysis, text mining, and text analytics. It helps machine learning models understand and interpret human language more accurately.
However, text annotation is not a one-size-fits-all process. Different types of annotations are used depending on the task at hand. These can range from entity recognition to sentiment annotation and linguistic annotation.
The quality of these annotations directly impacts the performance of machine learning models. Therefore, it’s essential to use effective strategies and tools for text annotation.
In this article, we’ll explore various text annotation strategies that can enhance machine learning models. We’ll also delve into the importance of text annotation in machine learning, its applications, and the tools and techniques used in the process.
Definition of Text Annotation
Text annotation is an essential technique that involves adding metadata to text data. This metadata provides additional information about specific words or phrases. It helps machines interpret text contextually. Text annotation can be defined as the practice of labeling text with tags or categories. This labeling can pertain to different aspects, such as the identification of entities, emotions, or language features.
Different kinds of annotations are applied based on the needs of the project. Some common annotation types include entity recognition, sentiment tagging, and linguistic annotation. Entity recognition, for example, involves marking text with named entities like people or organizations. Linguistic annotations might include syntactic elements such as parts of speech or semantic roles within the text. All these categories of annotations are pivotal. They help structure unorganized text for machine learning processes.
By annotating text, we prepare raw data so that machine learning models can grasp and leverage its information efficiently.
Importance in Machine Learning
Text annotation plays a pivotal role in machine learning, especially in natural language processing (NLP). It forms the foundation for training data used by algorithms to learn patterns. Machine learning models depend heavily on annotated text to draw inferences
and make predictions. Without proper annotation, models may struggle to understand the nuances of human language.
Annotated text provides structured and contextualized data, which is crucial. This well-labelled data allows models to recognize sentiment, identify entities, or decipher relationships within text. For sentiment analysis, for instance, text annotations help determine the underlying mood of a phrase or document. In this way, they empower algorithms to derive insights beyond basic pattern recognition.
Furthermore, the quality and type of annotation directly influence model efficiency and accuracy. Poorly annotated data can lead to flawed algorithms that misinterpret inputs. Therefore, effective text annotation ensures that models can comprehend, process, and provide reliable results. This importance underscores the need for robust annotation practices to bolster machine learning endeavors.
Types of Text Annotation
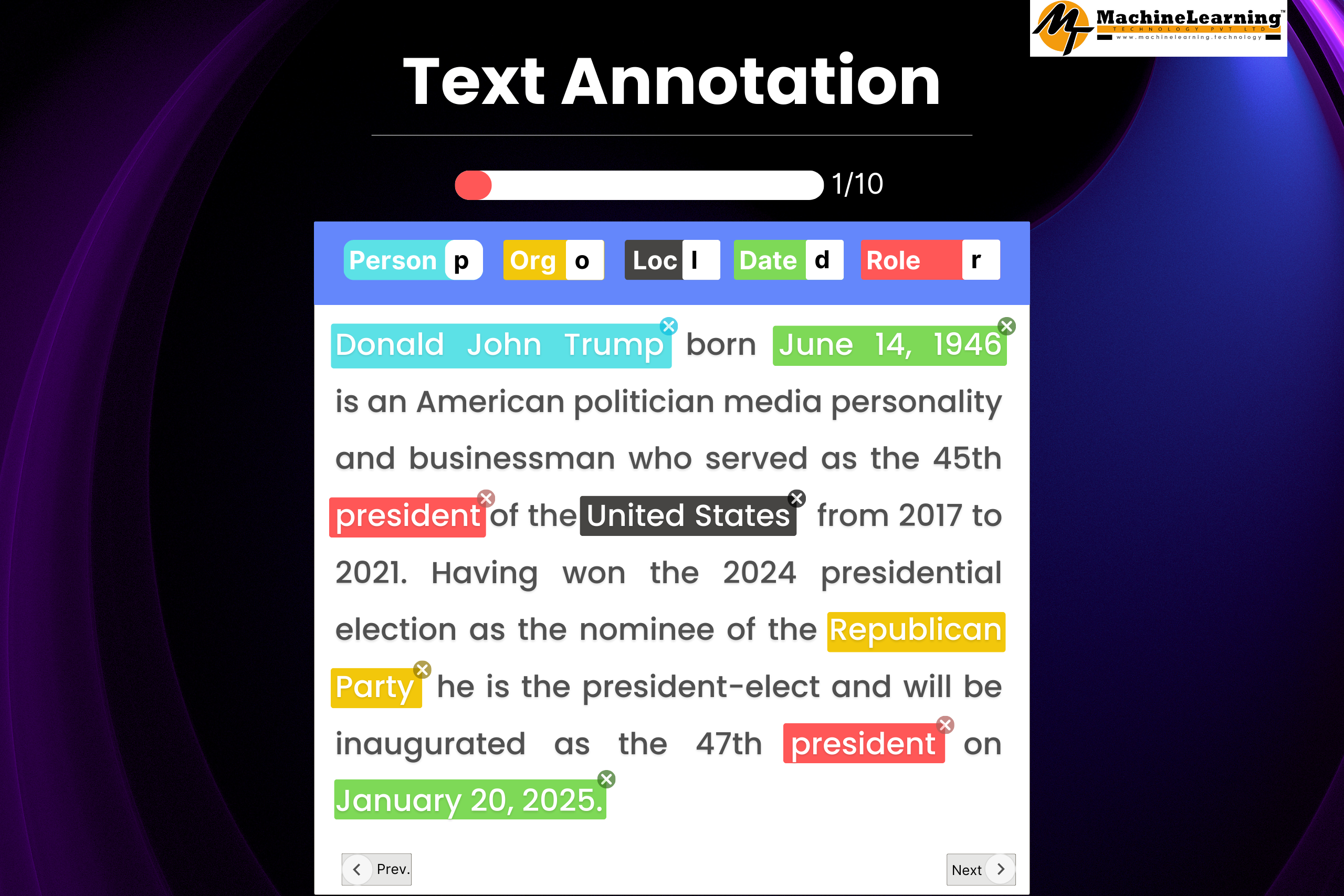
Entity Recognition
Entity recognition focuses on identifying key elements within a text. These elements often include names, places, and organizations, collectively known as named entities. Recognizing such entities enables machine learning models to classify and organize information effectively. For instance, differentiating between “Paris” as a city and a person’s name is crucial in context understanding.
This type of annotation is particularly useful in applications like information retrieval and question answering systems. It helps systems pinpoint precise data from vast text sources. In financial texts, for instance, correctly identifying companies or stock names is vital for analysts. Techniques in entity recognition involve carefully scanning and labelling text to improve model precision.
Thus, entity recognition serves as a backbone for various NLP tasks. It ensures that machine learning algorithms can accurately relate different parts of a text to the right entities.
Sentiment Analysis
Sentiment analysis annotation is all about identifying emotional undertones in text. It involves categorizing text based on the emotion or sentiment conveyed. Typical labels might include positive, negative, or neutral sentiments. This type of annotation is crucial for gauging public opinion, such as in product reviews or social media posts.
Sentiment annotations allow algorithms to detect emotions at scale, helping businesses understand consumer attitudes. They are particularly pivotal in fields like customer service and market research. Automated sentiment analysis, however, can
struggle with nuances like sarcasm or irony. Therefore, precise human annotation often enhances machine learning models’ effectiveness.
Through accurate sentiment analysis annotations, models can learn to better predict and assess sentiment trends. Thus, enhancing their application in real-world scenarios where understanding mood matters.
Part-of-Speech Tagging
Part-of-speech tagging, or POS tagging, labels words based on their grammatical role. This could include categories like nouns, verbs, adjectives, and adverbs. It provides a foundational layer for linguistic analysis in text, enabling deeper understanding. By tagging parts of speech, models can discern syntax and structure, enhancing their processing capabilities.
POS tagging is fundamental in text parsing and plays a critical role in applications like speech recognition and text-to-speech systems. Correct tagging ensures that sentences are grammatically understood, paving the way for further linguistic analysis. Machine learning models utilize these tags to better process language constructs.
Accurate part-of-speech annotations improve the model’s parsing efficacy. They allow for clear insights into language mechanics, essential for nuanced applications like language translation or syntactic analysis.
Text Annotation in Machine Learning
Role in Training Data
Text annotation plays a pivotal role in preparing training data for machine learning models. Properly annotated data enables models to learn patterns and features necessary for accurate predictions. For text-based machine learning tasks, annotations provide context and meaning, guiding models in interpreting raw data.
In natural language processing, annotated datasets train models to understand nuances and complexities of human language. This preparation is critical in fields like sentiment analysis, where emotional undertones need to be clearly identified. Annotation ensures that models can differentiate between similar words with different meanings based on context.
Moreover, high-quality annotations help reduce ambiguity. They allow machine learning algorithms to establish relationships between words, phrases, and sentences. This process, crucially, facilitates language comprehension beyond surface-level reading. Ultimately, effective text annotation leads to robust training data, supporting the creation of reliable and intelligent models.
Enhancing Model Accuracy
Accurate annotations are integral to enhancing the performance and precision of machine learning models. These annotations serve as the ground truth against which models are trained and evaluated. When data is meticulously annotated, models can achieve higher accuracy, as they better understand text intricacies.
Machine learning models leverage these annotations to refine their predictions. For example, in text mining, annotated datasets help in extracting meaningful insights from a sea of unstructured data. Through repeated training on well-annotated data, models can adjust their parameters and improve over time.
In addition, annotations aid in reducing model bias by providing diverse training instances. By including a variety of annotated examples, models gain a comprehensive understanding of language patterns. This approach minimizes the risk of error, particularly in recognizing diverse language constructs and sentiments.
Challenges and Solutions
Text annotation is fraught with challenges, primarily due to its labor-intensive nature. Manual annotation demands significant time and expertise, resulting in higher costs. Despite the availability of automated tools, manual oversight is often needed to ensure accuracy.
One solution lies in hybrid approaches, combining automated tools with human reviews. Such strategies maintain efficiency without sacrificing precision. Automated tools can handle basic tasks, while humans tackle complex aspects like understanding context or ambiguity.
Another significant challenge is ensuring consistency in annotations. Inter-annotator agreement metrics help monitor this by comparing the consistency across different annotators. Establishing clear guidelines can further support consistent results.
Furthermore, crowdsourcing offers a scalable solution to annotation needs. It involves a large number of people working on a project, expediting the process. However, it requires robust quality control to maintain high standards. Ultimately, overcoming these challenges involves balancing technology with human expertise to achieve optimal annotation outcomes.
Applications in Natural Language Processing (NLP)
Text Mining
Text mining is a powerful tool for uncovering insights from vast amounts of unstructured text. By extracting relevant information, text mining enables organizations to make data-driven decisions. Text annotation plays a crucial role in this process by labeling important data points that facilitate machine learning algorithms’ understanding.
Annotated data allows text mining tools to identify patterns, trends, and relationships within text. For instance, it can highlight common themes or emerging topics across social media platforms, aiding in market research. Annotations also help in identifying keywords and entities, such as names or locations, which are essential for deeper analysis.
Moreover, annotations ensure that mined data is contextual and meaningful. This enhances the accuracy of sentiment analysis, a subset of text mining, which interprets emotions and opinions expressed in the text. With proper annotation, text mining can transform raw data into actionable insights that drive strategic initiatives.
Text Analytics
In text analytics, the process of examining and processing text to extract meaningful information relies heavily on annotation. Annotated text data serves as the foundation for algorithms that analyse and interpret complex language structures. This is vital in applications such as customer feedback analysis, where understanding nuances can lead to better service and product improvements.
Text annotation contributes to text analytics by enabling the categorization and classification of data according to topics, sentiments, or intents. This organization helps businesses identify areas for growth and measure performance through sentiment analysis. For instance, customer reviews can be annotated to distinguish between positive and negative feedback.
Additionally, annotation facilitates the extraction of quantitative metrics from qualitative text, like identifying the frequency of certain sentiments. This ability to quantify text data enhances the predictive power of text analytics, transforming qualitative insights into measurable outcomes. Ultimately, well-annotated data empowers text analytics to deliver in-depth analysis crucial for informed decision-making.
Tools and Techniques
Popular Annotation Tools
Choosing the right annotation tools is crucial for efficient and accurate text annotation. Popular tools vary in their features, but they commonly offer user-friendly interfaces and support for multiple annotation types, such as Named Entity Recognition and sentiment analysis.
One example is Prodigy, which boasts a streamlined workflow and active learning capabilities. This tool suggests annotations based on the model’s output, helping annotators focus on the most informative examples. It’s particularly useful for iterative improvements in model accuracy.
Another option is Label box, which provides robust collaboration features for teams working on large datasets. Its extensive API integrations facilitate seamless interactions with other machine learning platforms. Label box also emphasizes quality control with features to manage annotation consistency.
For those looking for open-source alternatives, tools like Doccano offer flexible customization to suit specific project needs. Doccano supports multiple languages and includes built-in machine learning models to accelerate the annotation process. Each of these tools has unique strengths, allowing organizations to tailor their annotation workflows effectively.
Strategies for Effective Annotation
Developing effective annotation strategies is key to enhancing the quality of machine learning models. Clear and detailed annotation guidelines ensure that annotators consistently label text according to specific objectives. These guidelines should address common ambiguities and provide examples for difficult cases.
Inter-annotator agreement is another critical aspect, which measures consistency across different annotators. Regularly checking this agreement helps identify potential discrepancies and refine instructions to achieve uniformity in annotations.
Incorporating domain expertise into the annotation process can greatly improve accuracy. Annotators with knowledge in the relevant field are better equipped to understand context, which leads to more precise annotations. This is particularly important in complex domains like medical or legal texts.
Additionally, using a combination of manual and automated methods can optimize efficiency. Pre-annotated data and machine learning-assisted annotation can reduce the workload on human annotators. This hybrid approach balances speed with accuracy, ensuring that large datasets are annotated effectively and within time constraints. Regular feedback loops between annotators and engineers can further refine the annotation process, adapting to new challenges as they arise.
Conclusion
Summary of Benefits
Text annotation is pivotal in refining machine learning models. By carefully labeling data, algorithms better comprehend context and meaning. This leads to enhanced accuracy, particularly in natural language processing, sentiment analysis, and text mining. Efficient annotation not only boosts performance but also drives innovation in text analytics. The use of structured annotation strategies, combining both manual and automated approaches, ensures data quality and consistency. Thus, the investment in meticulous text annotation processes pays dividends in model robustness and reliability.
Future Trends
Looking ahead, text annotation is set to evolve with technological advancements. Machine learning models will increasingly assist annotators, identifying patterns and suggesting labels. This could significantly speed up the annotation process. Crowdsourcing and collaborative platforms may expand, making annotation more accessible globally. Furthermore, as natural language processing applications diversify, domain-specific annotations and ontologies will become essential. The focus on multilingual annotation will grow, addressing cultural nuances. The integration of real-time feedback loops will further refine annotation quality, ensuring data keeps pace with linguistic changes.

