Artificial Intelligence (AI) and Machine Learning (ML) are rapidly evolving. AIVIA has developed various ways of automating the healthcare and medical industries. Every AI and ML model requires data annotation at its core. This is akin to labeling data in a way that machines understand it. From marking images for self-driving cars to audio transcription for virtual assistants to classifying texts according to the emotions behind them annotation helps build intelligent systems.
This blog addresses key challenges in AI data annotation and proposes steps to help researchers and organizations create more accurate and reliable AI models. Overcoming these challenges can lead to significant advancements in AI and ML, inspiring further innovation and progress.
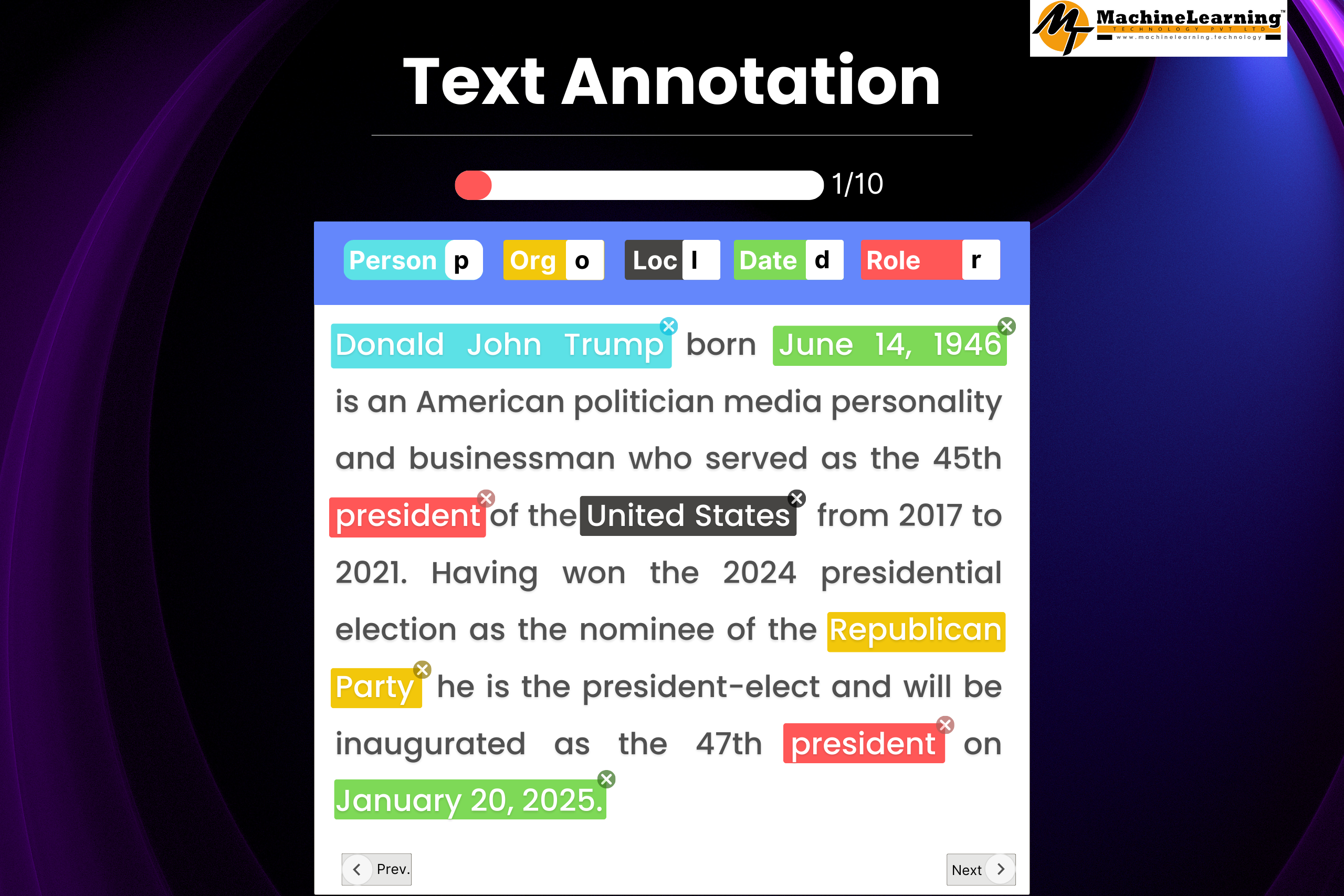
10 Challenges and Their Solution in AI Data Annotation

Overcoming Challenges of AI Data Annotation Quality and Consistency
Challenges:
- During the training and assessment phases, unclear annotations muddle the functioning of the models.
- Due to personal biases or lack of experience, different annotators can have varying perceptions of the same data.
- Poor or vague annotation instructions are especially problematic for edge cases or overlaps among categories due to ambiguity.
Solutions:
- Develop well-structured and organized annotation manuals that contain detailed definitions, instructions, and visual/textual examples for all data categories.
- Monitor the reliability of maximum annotator agreement metrics (Cohen’s Kappa, Krippendorff’s Alpha) to track annotator performance over time.
- Schedule regular training and calibration sessions to minimize individual subjectivity and enhance alignment among annotators.
- Establish a multi-layered quality control system where senior annotators or domain experts validate a subset of annotations to provide feedback to the team.
Managing Large-Scale Datasets Efficiently
Challenges:
- The cost and time required to annotate millions of data points manually are exorbitant, especially when resources are limited.
- With increasing volume, error rates rise due to quality control becoming more complex, further complicating matters.
- Slowing down the pace of model development, testing, and deployment is caused by annotation delays.
Solutions:
- Apply active learning methods in which the AI model determines the most uncertain or valuable samples for human annotation, thus decreasing the amount of data that needs to be reviewed.
- Utilize crowdsourcing platforms (like Appen and Amazon Mechanical Turk) to satisfy trivial annotation processes through a more widespread workforce quickly.
- Implement AI pre-annotation tools that automatically label notes using prior models for annotators to verify or correct rather than starting from scratch.
- Split the annotation process into contributing workflows (like QA, error correction, and data labeling) to increase productivity and workflow efficiency.
Handling Ambiguous and Subjective Data
Challenges:
- Some data (e.g., sarcastic tweets, complex emotions, fuzzy pictures) does not have an unambiguous designation or label.
- Subjective tasks like sentiment or emotion identification are open to personal or cultural biases.
- A lack of agreement among the raters can compromise the data quality, thus reducing the precision of the model.
Solutions:
- Allow annotators to grade the quality of each annotation and flag those that are uncertain or out of scope.
- Implement a multi-pass annotation strategy, where multiple annotations are done on the same data, and flags of disagreement are made for arbitration.
- Create a system where the annotator and the reviewer can work together to resolve discrepancies, allowing both parties to modify instructions from patterns or changes implemented.
- Engage domain experts/specialists for more problematic or controversial datasets, such as medical records and legal documents, to ensure correctness and pertinent accuracy.
Dealing with Data Imbalance
Challenges:
- Assets often possess class skewness (e.g., fewer fraudulent transactions compared to a more significant number of legitimate transactions), as is usually the case in the real world, making it hard for models to accommodate minority classes.
- This leads to poor generalization, increased false negatives, and a biased impact on critical cases.
Solutions:
- Implement augmentative treatments (e.g., rotating photos, rewriting texts) to minority classes to improve their representation.
- Implement stratified sampling to guarantee that every class is represented equally in the training, validation, and testing splits.
- Employ weighted loss functions (e.g., focal loss) in training models to address importance distribution and provide greater emphasis to errors made on the minority class.
- Investigate few-shot and transfer learning concepts, which aim to help the model with richer data and training versus sparse data for super rare or underrepresented classes.
Maintaining Data Security and Privacy Compliance
Challenges:
- Annotations may include sensitive or regulated information (such as medical, financial, and other data) that require strict data privacy measures and safeguards.
- Mishandling or unauthorized access may result in legal exposure, data breaches, and brand value risks.
- Legal frameworks such as GDPR, HIPAA, and CCPA are prerequisites for data security throughout its lifecycle.
Solutions:
- Execute data anonymization or pseudonymization and remove PII such as names, addresses, and SSNs before annotation.
- Employ role-based access controls (RBAC) for specific data types or projects so only users with permission can view the data.
- Provide secure data storage and transfer facilities, such as encrypted cloud storage, VPNs, and secure APIs.
- Hold regular privacy awareness sessions for all annotators handling private and legally sensitive information.

High Costs Associated with AI Data Annotation
Challenges:
- Professional or domain expert annotator personnel (such as radiologists or lawyers) can be costly to hire.
- Exponentially more extensive data sets increase costs, and so do the timelines for completing the projects.
- Frequent model modifications need constant data and annotation spending.
Solutions:
- Apply semi-supervised learning techniques, where the annotator labels a small fraction of the data, and the model predicts the labels for the remaining data.
- For non-creative and repetitive work, use crowdsourcing to lower the costs associated with labor.
- Use easy-to-integrate pre-annotation automation tools to reduce the time spent on manual labor.
- Where real-life data is complex to capture or annotate on a large scale, simulate or use AI (e.g., GANs) to create synthetic data.
Addressing Bias in AI Data Annotation
Challenges:
- Whether intentional or unintentional, human biases can exist in the labels and be reproduced by AI models.
- Gender, cultural, and racial biases tend to have discriminatory outcomes in especially sensitive cases such as employment or law enforcement.
- Bias from the annotator can influence the subjective interpretation of data.
Solutions:
- Aim to reduce bias by employing annotators from different cultures, demographics, and professional lines.
- Scan training datasets and their annotation outputs for patterns that illustrate bias in the data.
- Implement algorithms that are cognizant of equity and can observe and counteract bias in model outputs.
- Implement neutral labeling instructions and bias awareness training that makes annotators aware of the impact of their labeling actions.
Managing Complex AI Data Annotation Workflows
Challenges:
- AI projects of significant scale require multiple steps and team collaboration, including data collection, annotation, quality assessment, validation, etc.
- Manual processes are inherently inefficient, prone to mistakes, and more challenging to scale.
- There is no clarity on the visibility of task progress and assignments, resulting in missed deadlines and varying output quality.
Solutions:
- Employ annotation software such as Labelbox, Scale AI, and Prodigy with built-in project management tools, issue tracking, and other collaborative features to make workflows more productive.
- Integrate dashboards and pipelines to automate assigning tasks to reviewers, validating the review, and reporting.
- Use vigilant tagging of a defined label set so that clear team or individual boundaries and responsibilities enforcers (labelers, validators, reviewers, project managers).
- Create hybrid workflows in which human users work on computer initial predictions, which are iteratively refined using a feedback loop (human-in-the-loop systems).
Ensuring Scalability for Evolving AI Needs
Challenges:
- There is an ever-increasing need for better training data and annotations because AI models and cases change continually.
- Trends and data shifts are constantly ongoing, and static or outdated datasets will hinder the model’s performance.
- The systematic control of annotation changes over different dataset versions may become cumbersome to track.
Solutions:
- Create a closed feedback loop data annotation pipeline for real-time comments, retraining, and annotation enhancements.
- Utilize dataset versioning systems, such as DVC or Weights and Biases, to monitor the data, labels, and alterations throughout a given period.
- Enact transfer learning and domain adaptation to allow the use of models with smaller sets of new data required.
- In production, perpetually supervise model behavior and use performance drops as a cue to invest in a fresh annotation cycle.
Keeping Up with Technological Advances in AI Data Annotation
Challenges:
- Due to heightened automation and Artificial Intelligence technologies, manual annotating techniques are proving to be less valuable.
- Staying ignorant of new approaches restrains growth in competitiveness.
- Business Process inefficiency defaults to innovation, leading to higher business expenses.
Solutions:
- Participate in AI conferences like CVPR or NeurIPS, read scholarly articles, or follow new tech websites.
- Research self-labeled the semi-supervised framework to reduce the manual labeling workload.
- Implement reinforcement learning with programmatic annotation and labeling to automate the annotation process.
- Promote industry-academia partnerships to keep up with changing practices and technology.
Conclusion
Despite its multifarious and meticulous nature, AI data annotation is vital for developing machine learning models. Mitigating bias, data security, scalability, and inconsistency can ensure an AI system’s reliability. As best practices, automation, active learning, and bias mitigation can help streamline and improve annotation teams’ workflows.
Adaptability is key for researchers and organizations as emerging technologies become available to optimize data annotation. AI’s many challenges can lead it toward more advanced, ethical, and precise annotation procedures.
Are you prepared to enhance your AI data annotation processes? Improve on these processes today and get ready to train AI models for a brighter tomorrow.